이번 포스트에서는 모든 종류의 문서를 검색할 수 있고 실시간에 가까운 검색능력을 가진 ElasticSearch에 대해서 알아볼 것이다. 익히 들어본 넷플릭스나 페이스북에서도 이 검색엔진을 사용한다.

1. Elastcisearch 란?
1-1. 텍스트, 숫자, 위치 기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 분산형 오픈 소스 검색 및 분석 엔진.
1-2. 간단한 REST API, 분산형 특징, 속도, 확장성으로 유명한 Elasticsearch는 데이터 수집, 보강, 저장, 분석, 시각화를 위한 오픈 소스 도구 모음인 Elastic Stack의 중심 구성 요소.
1-3. 애플리케이션 검색, 웹사이트 검색, 로깅과 로그 분석, 애플리케이션 성능 모니터링, 위치 기반 정보 데이터 분석 및 시각화, 보안 분석, 비즈니스 분석 등에 사용됨.
1-4. *인덱스는 서로 관련되어 있는 문서들의 모음.
1-5. Elasticsearch는 JSON 문서로 데이터를 저장.
1-6. 각 문서는 일련의 키(필드나 속성의 이름)와 그에 해당하는 값(문자열, 숫자, 부울, 날짜, 값의 배열, 지리적 위치 또는 기타 데이터 유형)을 서로 연결.
1-7. *반전된 인덱스라고 하는 데이터 구조를 사용.
- 반전된 인덱스는 문서에 나타나는 모든 고유한 단어의 목록을 만들고, 각 단어가 발생하는 모든 문서를 식별.
- 전체 텍스트 검색을 아주 빠르게 할 수 있도록 설계됨.
1-8. 저장된 문서는 *샤드라고 하는 여러 다른 컨테이너에 걸쳐 분산됨.
- 이 샤드는 복제되어 하드웨어 장애 시에 중복되는 데이터 사본을 제공.
1-9. 주요 특징.
- 검색이 빠름. 대기시간이 보통 1초 정도.
- 분산처리.
- 다양한 기능을 제공.
- 데이터 수집, 시각화, 보고를 간소화.
1-10. 공식 문서.
- https://www.elastic.co/kr/what-is/elasticsearch
What is Elasticsearch | Elastic
Elasticsearch는 텍스트, 숫자, 위치 기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 분산형 오픈 소스 검색 및 분석 엔진입니다. Elasticsearch는 Apache Lucene을 기반으로 구축되며, (현재 Elastic이라고 알려져 있는) Elasticsearch N.V.가 2010년에 최초로 출시했습니다. 간단한 REST API, 분산형 특징, 속도, 확장성으로 유명한 Elasticsearch는 데이터 수집, 보강, 저
www.elastic.co
2. 설치.
2-1. 다운로드.
- elasticsearch-7-3-1 다운로드
2-2. 압축해제.
- [ C:\work\elasticsearch-7.3.1 ]에 압축해제.
2-3. 파일확인.
- config 폴더에 [ elasticsearch.yml, jvm.options, log4j2.properties ]있는데 이 3개는 반드시 있어야 함.
- jdk가 같이 설치됨.

3. Elasticsearch 설정 및 실행.
- 작업폴더: C:\work\elasticsearch-7.3.1
3-1. [ ./conf.d ] 폴더 생성 및 파일 생성.
- 폴더를 생성하고 [ ./config ] 폴더에 있는 [ elasticsearch.yml, jvm.options, log4j2.properties ]를 복사.
3-2. [ ./conf.d/elasticsearch.yml ] 수정.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
cluster.name: dochi-cluster
node:
name: node-1
master: true
data: true
path:
data: C:/work/elasticsearch-7.3.1/data
logs: C:/work/elasticsearch-7.3.1/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts:
- 0.0.0.0:9300
|
cs |
- 1 ln: 클러스터명, 시스템 노드의 클러스터명과 겹치지 않게 주의해야 함.
- 4 ln: *노드의 이름.
- 5~6 ln: 하나의 노드 클러스터이기 때문에 마스터, 데이터 노드 역할을 부여함.
- 8~10 ln: 데이터 및 로그 경로 지정.
- 12 ln: Elasticsearch에 할당된 메모리를 고정.
- 14~15 ln: 노드가 클러스터에 접근하기 위한 IP와 Port.
- 16 ln: 노드간에 통신을 위한 Port.
- 18 ln: Zen Discovery는 기본으로 제공하는 검색 모듈이며 마스터 노드와 통신하기위한 주소.
3-3. *노드란?

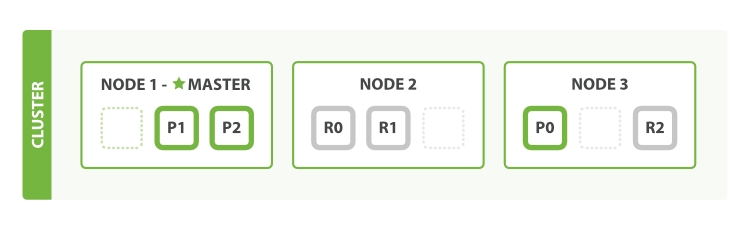
- Elasticsearch 인스턴스를 시작할 때마다 노드가 시작됨.
- 연결된 노드의 모음을 클러스터라고 함.
- 같은 클러스터 내의 노드끼리만 조인이 가능함.
- 여러개의 샤드로 구성됨.
- 종류는 Master-Eligible, Data, Ingest, Coordinating, Machine Learning 노드로 5가지가 있음.
- 1개의 클러스터에 1개의 노드만 사용하는 경우 장애시 데이터 손실이 발생할 수 있으며, 검색 성능이 떨어짐.
- 클러스터가 커질수록 각 역할을 나눈 노드를 구성하는 것이 좋음.
- 더 자세한 내용은 공식 문서 참조.
Node | Elasticsearch Reference [7.x] | Elastic
When using the .zip or .tar.gz distributions, the path.data setting should be configured to locate the data directory outside the Elasticsearch home directory, so that the home directory can be deleted without deleting your data! The RPM and Debian distrib
www.elastic.co
3-4. [ ./elasticsearch_start.bat ] 작성.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
rem elasticsearch_start.bat
@echo off
rem 현재 디렉토리 설정
pushd %~dp0
set ES_HOME=%cd%
popd
set JAVA_HOME=%ES_HOME%\jdk
set ES_PATH_CONF=%ES_HOME%\conf.d
%ES_HOME%\bin\elasticsearch
|
cs |
3-5. [ ./elasticsearch_start.bat ] 실행.

- 실행이 완료되면 브라우저를 실행하고 [ http://localhost:9200/ ]를 입력해보자.

- Elasticsearch는 RESTful API로 조회하는 검색엔진이기 때문에 모니터링 화면이 없는 지금은 Postman을 이용하는 것을 추천.
- [ http://localhost:9200/_cat ]에 접속하여 다냥한 지원 기능들도 확인할 수 있음.

4. 마치며.
- 이번 포스트에서는 Elasticsearch에 대하여 알아보았다. 간단하게 설치만하고 실행만 하려고 했는데도 이것저것 알고가야 하는 것들이 많아서 생각보다 어려웠다.
- 다음 포스트에서는 Flume에서 데이터를 수집하여 Index를 생성하고 간단하게 검색을 해보도록 하겠다.
#참고사이트
- http://kimjmin.net/2018/01/2018-01-build-es-cluster-5/
- https://oboki.net/workspace/bigdata/elasticsearch/elasticsearch-configuration/
댓글