2020/01/10 - [Back-end/Python] - [Celery] 무작정 시작하기 (1) - 설치 및 실행
2020/01/17 - [Back-end/Python] - [Celery] 무작정 시작하기 (2) - Task
2020/01/20 - [Back-end/Python] - [Celery] 무작정 시작하기 (3) - Chain
지난 포스트에서는 Chain을 이용하여 Taks를 순차적으로 실행시키는 방법을 알아보았다. 이번 포스트에서는 Task를 일괄적으로 실핼 할 수 있는 Group과 Chord에 대해서 알아보려고 한다.
1. Group이란?
1-1. 말 그대로 하나의 집합을 만들어 실행시키는 작업으로 Task를 병렬로 실행할 수 있음.
1-2. Task를 그룹화 하는 방법에는 두가지가 있음.
- 비트연산자( | )를 이용하는 방법: Chain과 같이 순차적으로 실행됨.
- 리스트 또는 튜플을 이용하는 방법: Task가 병렬로 수행되며 결과는 리스트로 반환됨.
1-3. Group은 병렬처리를 하기 때문에 Worker의 옵션을 변경해주어야함.
- [ -P | --pool ]: solo가 아닌 다른 옵션으로 설정, prefork, threads, gevent, eventlet, default: profork.
- [ -c | --concurrency ]: 병렬처리할 수 있는 수를 2이상 주어야함.
|
1
2
3
|
celery -A dochi_app worker -l INFO -P threads -c 10
#또는
celery worker --app=dochi_app --loglevel=INFO --pool=threads--concurrency=10
|
cs |
1-4. Group의 결과는 <class 'celery.result.GroupResult'>인데, successful(), failed와 같이 특수한 기능이 제공됨.
1-5. 더 자세한 내용은 공식 문서를 참고.
2. 예제 소스.
2-1. 1~5까지 연속하는 두 수 더하기.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# run_chain.py
from tasks import calc
from celery import group
tasks = [ calc.add.s( i, i+1 ) for i in range(1, 5) ]
grouping = group( tasks )
group_task = grouping() # 또는 grouping.apply_async()
print( "\n# 1. Task 확인" )
print( "tasks = {}".format( tasks ) )
print( "group_task.id = {}".format( group_task.id ) )
print( "group_task.type = {}".format( type(group_task) ) )
print( "\n# 2. Task 상태 확인" )
print( "Subtask가 모두 준비되었는가? {}".format( group_task.ready() ) )
print( "\n# 3. 실행결과 확인" )
print( "몇건이 완료 되었는가? {}".format( group_task.completed_count() ) )
print( "완료된 결과를 반환. {}".format( group_task.get() ) )
print( "호출한 순서대로 반환. {}".format( group_task.join() ) )
print( "몇건이 완료 되었는가? {}".format( group_task.completed_count() ) )
print( "\n# 4. Task 상태 확인" )
print( "Subtask가 모두 준비되었는가? {}".format( group_task.ready() ) )
print( "모두 성공했는가? {}".format( group_task.successful() ) )
print( "실패가 있는가? {}".format( group_task.failed() ) )
|
cs |
- 5 ln: 1~5까지 연속하는 두수 더하는 subtask 목록 생성.
- 7 ln: group 모듈로 subtask를 그룹화.
- 8 ln: group화된 Task를 실행.
2-2. 실행결과.

- group_task.type이 <class 'celery.result.GroupResult'>인 것으로 확인됨.
- 결과값이 리스트로 반환됨, get()과 join() 함수로 결과를 받을 수 있음.
2-3. Celery 로그 확인.
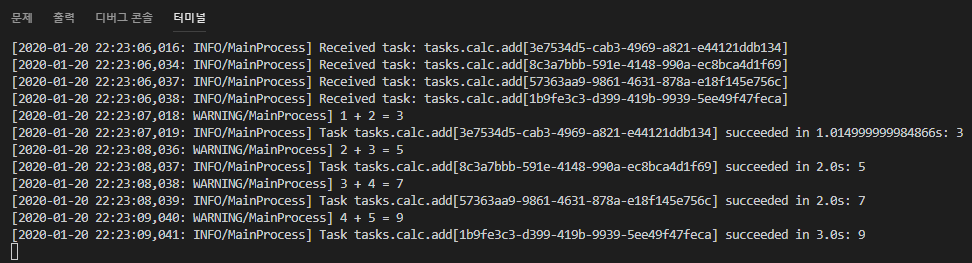
- Received가 먼저 되는것으로 보아 Task가 병렬처리되는 것으로 확인됨.
- Task에 Sleep을 Random하게 주면 좀 더 명확하게 확인할 수 있음.
3. Chord란?
3-1. 사전적 의미로는 화음이라고 하며, 그룹의 모든 작업이 완료된 후에만 실행되는 작업.
3-2. Group에 다른 Task를 연결하면 Chord로 업그레이드됨.
예) group( tasks ) | task
3-3. Group과는 다르게 결과를 반환받을 Callback이 있어야함.
3-4. 주의사항의 매우 많음.
- 결과값을 무조건 반환받아야 함, ignore_result=False.
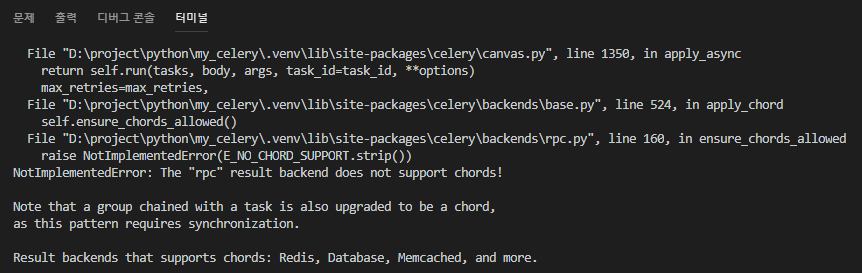
- Result Backend로 RabbitMQ/rpc를 지원하지않음.
- Message 처리와 동기화의 오버 헤드로 속도가 느림.
- 동기화 단계는 비용이 많이 들기 때문에 Chord의 사용을 최대한 피하는 것을 권장.
3-5. 더 자세한 내용은 공식 문서를 참고.
4. 시작하기전에...
4-1. 위에서 정리했듯이 Chord에서는 Result Backend로 RabbitMQ/rpc를 지원하지않음.
- 우리는 지난 포스트에서 rpc로 설정했기 때문에 변경이 필요함.
4-2. Celery App 설정 변경.
- dochi_app.py 수정.
|
1
2
3
4
5
6
7
8
9
10
11
|
from celery import Celery
app = Celery(
'my_tasks'
, broker='amqp://heo:heo@localhost:5672//'
, backend='amqp://' # rpc -> amqp
, include=[
'tasks.example'
, 'tasks.calc'
]
)
|
cs |
- 6 ln: rpc에서 amqp로 변경.
* 사실 amqp도 권장하지않는 방법인데 우선 돌아가기 때문에 테스트용으로 사용할 계획임.
* Redis나 Memcached를 사용하는 것을 권장함.
4-3. 한가지 더, Chord는 결과를 반환받을 Callback 함수가 있어야함.
- tasks/calc.py 수정.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import time
import random
from dochi_app import app
@app.task
def add( num1, num2 ):
time.sleep( random.randint(1, 10) )
print( "{} + {} = {}".format( num1, num2, num1+num2 ) )
return num1 + num2
@app.task
def callback( results ):
return sum(results)
|
cs |
- 15 ln: results에는 모든 subtask의 결과값이 리스트에 담겨있음.
4-3. Celery 실행 확인.
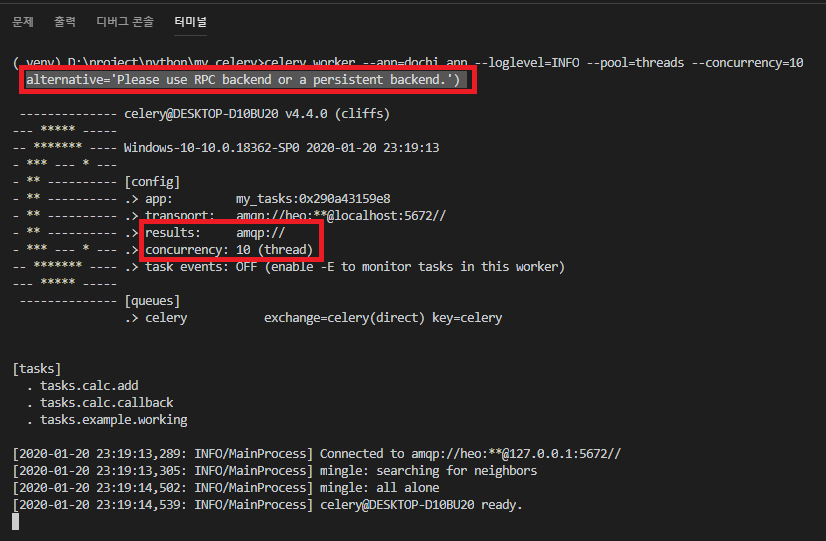
- RPC나 지속성있는 Backend를 사용해달라고 하지만, 테스트용 이기때문에 무시하고 넘어가자.
5. 예제 소스.
5-1. 1~5까지 연속하는 두 수를 더한 총합을 구하시오.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# run_chain.py
from tasks import calc
from celery import chord
tasks = [ calc.add.s( i, i+1 ) for i in range(1, 5) ]
chording = chord( tasks )
chord_task = chording( calc.callback.s() )
print( "\n# 1. Task 확인" )
print( "tasks = {}".format( tasks ) )
print( "chord_task.id = {}".format( chord_task.id ) )
print( "chord_task.type = {}".format( type(chord_task) ) )
print( "\n# 2. Task 상태 확인" )
print( "Subtask가 모두 준비되었는가? {}".format( chord_task.ready() ) )
print( "\n# 3. 실행결과 확인" )
print( "완료된 결과를 반환. {}".format( chord_task.get() ) )
print( "\n# 4. Task 상태 확인" )
print( "Subtask가 모두 준비되었는가? {}".format( chord_task.ready() ) )
|
cs |
- 7 ln: 그룹화된 chord task를 생성.
- 8 ln: 위에서 정의한 callback을 subtask를 통해 결과를 반환받음.
5-2. 실행 확인.

- chord_task.type이 <class 'celery.result.AsyncResult'>인 것으로 확인됨.
- Groupd에서 사용했던 successful(), failed(), join() 등의 기능을 사용할 수 없음.
- Group은 병렬처리가 된 후에 결과값을 리스트로 반환하여 그대로 출력되지만, Chord는 callback에서 후 처리를 할 수 있어서 모두 더한 값을 바로 출력하였음.
5-3. Celery 로그 확인.

- Group과 마찬가지로 Received가 먼저 되는것으로 보아 Task가 병렬처리되는 것으로 확인됨.
6. 마치며.
- 처음에는 Group과 Chord의 차이가 긴가민가해서 잘 이해가 가지않았는데, 정리하면서 보니까 Chord은 callback으로 결과값을 핸들링할 수 있다는 큰 차이를 알게되었다.
- 마땅히 적용해볼만한 예제가 떠오르지 않는다. 크롤러를 만들어보면서 직접 사용해봐야겠다.
- 그리고 지금까지 Celery를 쓰면서 로그만 확인했었는데, 모니터링 툴을 한번 써보도록 하겠다.
참고사이트
- https://docs.celeryproject.org/en/latest/userguide/canvas.html#chord-important-notes
'Back-end > Python' 카테고리의 다른 글
| [크롤링] 직방에서 방찾기 (2) - Crawler (0) | 2020.01.21 |
|---|---|
| [크롤링] 직방에서 방찾기 (1) - 데이터 분석 (2) | 2020.01.21 |
| [Celery] 무작정 시작하기 (3) - Chain (0) | 2020.01.20 |
| [Celery] 무작정 시작하기 (2) - Task (1) | 2020.01.17 |
| [Selenium] Chrome에서 탭 여러개 사용하기 (4) | 2020.01.16 |




댓글