2020. 2. 2. 18:06ㆍBack-end/Python
2020/01/31 - [Back-end/Python] - [크롤링] Selenium으로 특가 상품 수집 (1) - 프로젝트 준비
2020/01/31 - [Back-end/Python] - [크롤링] Selenium으로 특가 상품 수집 (2) - Selenium 설정
2020/01/31 - [Back-end/Python] - [크롤링] Selenium으로 특가 상품 수집 (3) - 데이터 분석 및 수집
지난 포스트에서 11번가에서 특가상품을 수집하는 크롤러를 만들어보았다. 지금은 11번가의 특가상품 하나만 수집하지만 앞으로 티몬, 위메프 등 수집대상을 늘려나갈 것이다. 그런데, 지금처럼 하나의 파이썬 파일에 크롤러를 작성해두면 소스를 관리하기도 어렵고 재사용하기도 어려워진다. 그래서, 이번 포스트에서는 앞서 만든 크롤러를 모듈화하여 프로젝트를 관리하고자 한다.
1. 프로젝트 구성.
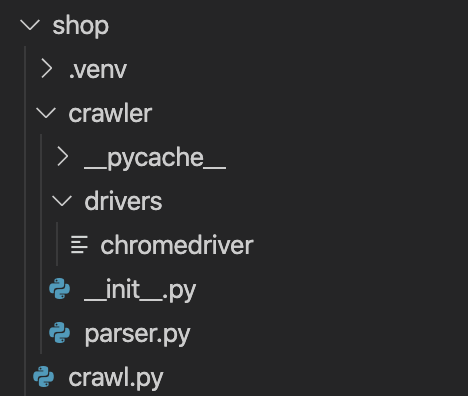
2. Crawler 모듈화.
2-1. Crawler Class 소스 작성.
- crawer/__init__.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class SeleniumRequest(object):
driver = None
chrome_options = Options()
def __init__(self, driver_path, options=None):
self.driver_path = driver_path
self.options = [ '--headless', '--log-level=3', '--disable-logging', '--no-sandbox', '--disable-gpu' ]
self._make_chrome_options( options )
self.driver = webdriver.Chrome( executable_path=self.driver_path, chrome_options=self.chrome_options)
def _make_chrome_options(self, options):
if options is not None:
self.options += options
self.chrome_options = Options()
for opt in set(self.options):
self.chrome_options.add_argument( opt )
def get( self, url, callback=None ):
self.driver.get( url )
return callback( response=self.driver )
|
cs |
- 4 ln: 크롤러를 class로 생성.
- 5~6 ln: 초기값 설정.
- 8 ln: __init__함수는 생성자 함수로, class를 객체로 생성할 때 실행됨.
* request = SeleniumRequest( 경로, options=옵션 )과 같이 객체를 생성하면 __init__함수가 실행됨.
- 9~11 ln: 초기값 설정.
- 13 ln: WebDriver 객체 생성.
- 15~21 ln: _make_chrome_options 함수는 배열에 저장된 옵션들을 WebDriver Options 객체로 만들어주는 함수.
- 23~25 ln: URL을 입력받아 Request를 요청하고 결과값을 반환하는 함수.
* callback 매개변수는 결과값을 파싱하는 함수를 인자값으로 받음.
* callback에 response 매개변수에는 페이지가 변경된 WebDriver를 인자값으로 전달.
2-2. 파싱 함수 소스 작성.
- crawler/parser.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
def st11_parser( response=None ):
datas = list()
elements = response.find_elements_by_xpath('//*[@id="emergencyPrd"]/div/ul/li[position()<=3]')
for idx, el in enumerate(elements):
el_title = el.find_element_by_xpath('div/a/div[3]/p/span')
el_price = el.find_element_by_xpath('div/a/div[3]/div/span[2]/strong')
el_link = el.find_element_by_xpath('div/a')
title = el_title.text.strip()
price = el_price.text.replace(',', '').strip()
link = el_link.get_attribute('href')
data = {
"no": idx+1
, "title": title
, "price": price
, "link": link
}
datas.append( data )
return datas
|
cs |
- 1 ln: 11번가 파싱함수이며, WebDriver를 매개변수로 받음.
- 2 ln: 파싱된 결과를 저장할 변수.
- 4 ln: 상품 목록을 탐색.
- 6 ln: 상품목록을 enumerate함수를 사용하여 인덱스와 데이터 추출함.
- 7~9 ln: 상품목록에서 상품명, 상품가격, 링크 Element를 탐색함.
- 11~13 ln: Element에서 데이터를 추출하고 가공함.
- 15~22 ln: 파싱된 데이터를 변수에 저장.
2-3. 실행 파일 작성.
- crawl.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
from crawler import SeleniumRequest
from crawler.parser import st11_parser
from pprint import pprint
targets = {
"11st": {
"url": 'http://deal.11st.co.kr/html/nc/deal/main.html'
, "parser": "st11_parser"
}
}
request = SeleniumRequest( driver_path='./crawler/drivers/chromedriver' )
for key in targets.keys():
info = targets[key]
url = info['url']
callback = eval(info["parser"])
data = request.get( url, callback=callback )
pprint( data )
|
cs |
- 1~2 ln: 위에서 만든 Crawler와 파싱 함수를 Import.
- 3 ln: 객체를 예쁘게 출력해주는 파이썬 내장 라이브러리.
- 5~10 ln: 크롤링할 대상의 url과 parser를 정의.
* parser를 문자열로 정의한 이유는 나중에 Database나 파일에서 대상을 가져와도 실행되도록 하기 위함.
- 12 ln: Crawler 객체 생성.
- 14~15 ln: 수집대상의 정보 가져오기.
- 18 ln: eval 함수를 통해 문자열로된 명령어를 실행.
* 여기서는 문자열로된 st11_parser함수를 callback에 저장하는 용도로 사용됨.
- 20 ln: 수집을 요청하고 결과값을 반환받음.
- 22 ln: 결과를 예쁘게 출력.
2-4. 실행.
> python crawl.py
2-5. 실행 결과.

- 3개의 상품 정보를 잘 수집해 온 것을 확인할 수 있음.
3. 티몬, 위메프 소스 추가.
3-1. 실행 소스 수정.
- crawl.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
from crawler import SeleniumRequest
from crawler.parser import st11_parser, tmon_parser, wemap_parser
from pprint import pprint
targets = {
"11st": {
"url": 'http://deal.11st.co.kr/html/nc/deal/main.html'
, "parser": "st11_parser"
, "data": None
},
"tmon": {
"url": 'http://www.tmon.co.kr/best/1'
, "parser": "tmon_parser"
, "data": None
},
"wemap": {
"url": 'https://front.wemakeprice.com/special/group/4000021'
, "parser": "wemap_parser"
, "data": None
}
}
def run( target ):
request = SeleniumRequest( driver_path='./crawler/drivers/chromedriver' )
info = targets[target]
url = info['url']
callback = eval(info["parser"])
data = request.get( url, callback=callback )
return data
if __name__ == '__main__':
request = SeleniumRequest( driver_path='./crawler/drivers/chromedriver' )
for key in targets.keys():
info = targets[key]
url = info['url']
callback = eval(info["parser"])
data = request.get( url, callback=callback )
targets[key]["data"] = data
pprint( targets )
|
cs |
- 23~33 ln: 대상을 입력받아 크롤러를 호출할 수 있도록 함수 추가.
- 36~48 ln: 현재 파일이 메인이 되어 실행되는 경우, 모두 탐색하도록 변경.
3-2. 파싱 함수 추가.
- crawler/parser.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
def st11_parser( response=None ):
datas = list()
elements = response.find_elements_by_xpath('//*[@id="emergencyPrd"]/div/ul/li[position()<=3]')
for idx, el in enumerate(elements):
el_title = el.find_element_by_xpath('div/a/div[3]/p/span')
el_price = el.find_element_by_xpath('div/a/div[3]/div/span[2]/strong')
el_link = el.find_element_by_xpath('div/a')
title = el_title.text.strip()
price = el_price.text.replace(',', '').strip()
link = el_link.get_attribute('href')
data = {
"no": idx+1
, "title": title
, "price": price
, "link": link
}
datas.append( data )
return datas
def tmon_parser( response=None ):
datas = list()
elements = response.find_elements_by_xpath('//*[@id="_dealList"]/li[position()<=3]')
for idx, el in enumerate(elements):
el_title = el.find_element_by_xpath('a/div/div[3]/p[2]')
el_price = el.find_element_by_xpath('a/div/div[3]/div[1]/span[1]/span/i')
el_link = el.find_element_by_xpath('a')
title = el_title.text.strip()
price = el_price.text.replace(',', '').strip()
link = el_link.get_attribute('href')
data = {
"no": idx+1
, "title": title
, "price": price
, "link": link
}
datas.append( data )
return datas
def wemap_parser( response=None ):
datas = list()
elements = response.find_elements_by_xpath('//*[@id="_contents"]/div/div[2]/div[3]/div[3]/div/a[position()<=3]')
for idx, el in enumerate(elements):
el_title = el.find_element_by_xpath('div/div[2]/div[2]/p')
el_price = el.find_element_by_xpath('div/div[2]/div[2]/div/div[2]/strong/em')
el_link = el
title = el_title.text.strip()
price = el_price.text.replace(',', '').strip()
link = el_link.get_attribute('href')
data = {
"no": idx+1
, "title": title
, "price": price
, "link": link
}
datas.append( data )
return datas
|
cs |
3-3. 실행.
> python crawl.py
3-4. 실행 결과.
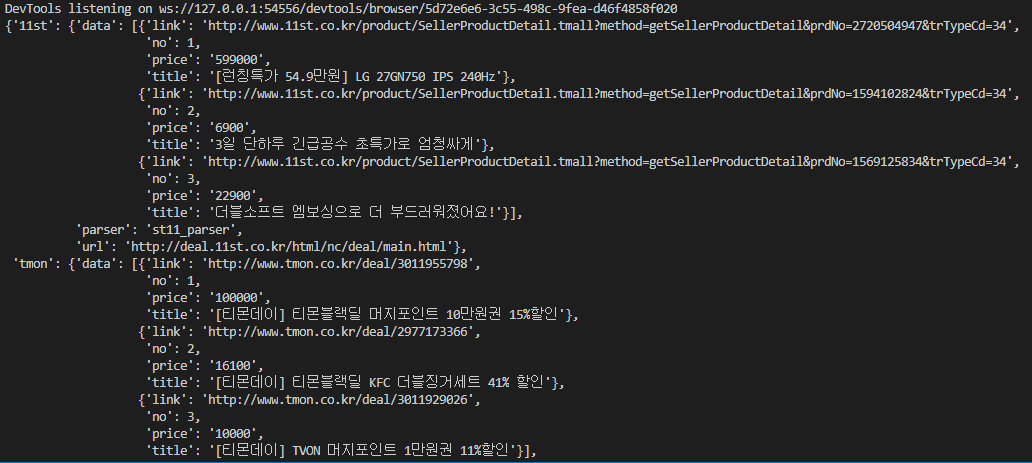
4. 마치며.
- 이것으로 Crawler를 모듈화하여 보았다. 이렇게 모듈화해두면 쇼핑몰 특가상품 뿐만아니라 url과 parser가 정의된 다른 사이트들을 크롤링할 때도 사용할 수 있다.
- SeleniumRequest의 get함수와 파싱 함수들에서 가변인자(*args, **kwargs)를 사용하면 상품의 수집개수를 입력받거나 특정 키워드가 포함된 상품을 조회하는 등의 설정을 할 수 있다. 어렵지않은 부분이지만 여기서 다루면 복잡해질것같아서 생략했다.
- 다음 포스트에서는 이번에 만든 Crawler를 가지고 텔레그램 봇을 통해서 조작하는 방법에 대해서 알아보도록 하겠다.
'Back-end > Python' 카테고리의 다른 글
| [Pyftpdlib] FTP 서버 만들기 (1) - 설치 및 실행 (0) | 2020.02.12 |
|---|---|
| [크롤링] Selenium으로 특가 상품 수집 (5) - Telegram Bot (0) | 2020.02.03 |
| [크롤링] Selenium으로 특가 상품 수집 (3) - 데이터 분석 및 수집 (2) | 2020.01.31 |
| [크롤링] Selenium으로 특가 상품 수집 (2) - Selenium 설정 (0) | 2020.01.31 |
| [크롤링] Selenium으로 특가 상품 수집 (1) - 프로젝트 준비 (0) | 2020.01.31 |