2020. 1. 31. 15:36ㆍBack-end/Python
2020/01/31 - [Back-end/Python] - [크롤링] Selenium으로 특가 상품 수집 (1) - 프로젝트 준비
지난 포스트에서 프로젝트 구성과 수집할 대상을 선정해보았다. Selenium을 Crawler로 사용하기로 하였는데, 사실 Selenium은 웹 어플리케이션을 테스트하기 위한 자동화 도구이지 크롤링을 위한 도구가 아니다. 그래서, Crawler로 사용하려면 필수는 아니지만 Selenium WebDriver에 몇가지 옵션을 설정해주는 것이 좋다. 이번 포스트에서는 Selenium을 설치하고 이 옵션을 설정하는 방법에 대해서 알아보도록 하겠다.
1. Selenium 설치 및 실행.
1-1. Selenium 설치.
> pip install selenium
1-2. 소스 작성.
- crawl.py
|
1
2
3
4
5
6
7
8
9
|
from selenium import webdriver
URL = 'http://deal.11st.co.kr/html/nc/deal/main.html'
DRIVER_PATH = './crawler/drivers/chromedriver.exe'
driver = webdriver.Chrome( executable_path=DRIVER_PATH )
driver.get( URL )
print( driver.page_source )
|
cs |
- 1 ln: Selenium으로 WebDriver를 실행시키는 모듈 Import.
- 3 ln: 수집 대상의 URL주소.
* 11번가 특가상품 페이지.
- 4 ln: 이전 포스트에서 설치한 Chrome WebDriver의 위치.
- 6 ln: Chrome WebDriver 객체 생성.
- 7 ln: URL을 요청하여 페이지를 변경함.
- 9 ln: 로드된 페이지의 소스를 출력.
1-3. 실행.
> python crawl.py
1-4. 실행 결과.

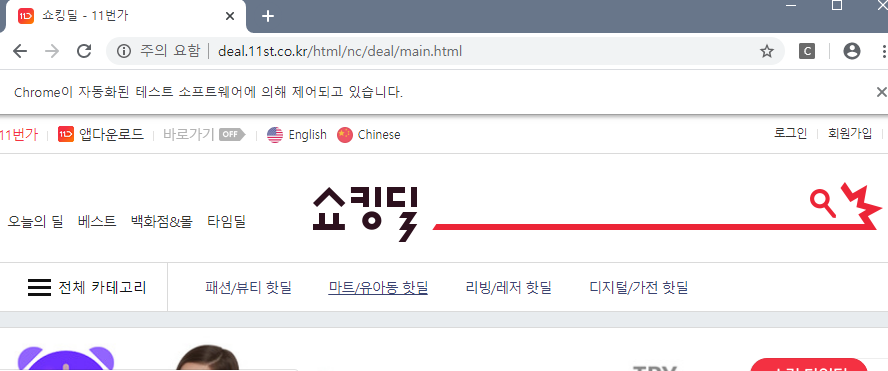
- Chrome WebDriver 객체가 생성되면 [실행 결과1] 같은 Browser가 실행됨.
- 페이지의 로드가 완료되면 설정한 URL로 페이지가 변경됨.
- 변경된 페이지도 로드가 완료되면 명령 프롬프트에 페이지 소스가 출력됨.
- 명령 프롬프트를 종료하거나 KeyboardInterrupt를 발생시키면 Browser가 종료됨.
1-5. 정리.
- Selenium은 웹 어플리케이션 테스트 도구이기 때문에 WebDriver에 의해 Browser가 실행됨.
- 크롤링에 문제가 되는 것은 아니지만, 크롤링 할 때 마다 Browser가 실행되고 GUI를 사용할 수 없는 환경에서는 실행할 수 없음.
- 로그인이 필요한 페이지의 경우 로그인 페이지로 이동되면서 예상과 다르게 동작하는 경우가 있는데, 이런 경우 Browser로 확인하면 좋음.
- BeautifulSoup4 패키지를 이용하여 페이지 소스를 파싱해서 사용해도 됨.
2. WebDriver 옵션 설정.
2-1. Browser 없이 WebDriver를 실행하는 옵션 적용.
- crawl.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
URL = 'http://deal.11st.co.kr/html/nc/deal/main.html'
DRIVER_PATH = './crawler/drivers/chromedriver.exe'
chrome_options = Options()
chrome_options.add_argument( '--headless' )
driver = webdriver.Chrome( executable_path=DRIVER_PATH, chrome_options=chrome_options )
driver.get( URL )
print( driver.page_source )
|
cs |
- 2 ln: Chrome WebDriver의 옵션을 설정하는 모듈 Import.
- 7~8 ln: 옵션 설정.
* [ --headless ]: WebDriver를 Browser 없이 실행하는 옵션.
- 10 ln: 옵션 적용.
2-2. 실행.
> python crawl.py
2-3. 실행 결과.
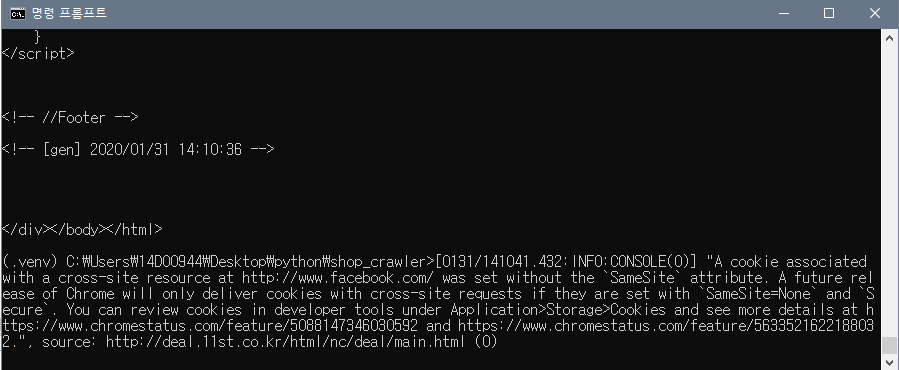
- Browser가 실행되지 않지만, Chrome Browser의 로그들이 명령프롬프트에 출력됨.
- Chrome Browser의 로그가 출력되면 수집된 데이터를 모니터링하기 힘들어짐.
2-4. Chrome Browser의 로그가 출력되지 않는 옵션 적용.
- crawl.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
URL = 'http://deal.11st.co.kr/html/nc/deal/main.html'
DRIVER_PATH = './crawler/drivers/chromedriver.exe'
chrome_options = Options()
chrome_options.add_argument( '--headless' )
chrome_options.add_argument( '--log-level=3' )
chrome_options.add_argument( '--disable-logging' )
driver = webdriver.Chrome( executable_path=DRIVER_PATH, chrome_options=chrome_options )
driver.get( URL )
print( driver.page_source )
|
cs |
- 9 ln: Chroem Browser의 로그 레벨을 낮추는 옵션.
- 10 ln: 로그를 남기지 않는 옵션.
* chromedriver의 버전에 따라 적용이 안될 수도 있지만, 로그 레벨만 낮춰도 로그가 출력되지 않음.
2-5. 실행.
> python crawl.py
2-6. 실행 결과.
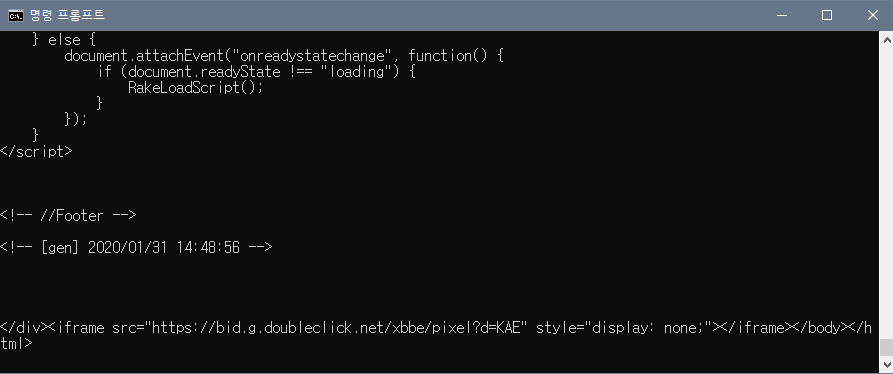
- 깔끔하게 페이지 소스만 출력되는 것을 확인 할 수 있음.
2-7. 정리.
- 리눅스 서버와 같이 GUI를 제공하지 않는 환경에서는 '--no-sandbox, --disable-gpu' 옵션도 추가해야함.
3. 마치며.
- 이번 포스트에서는 Selenium WebDrvier를 Crawler로 사용하기위한 옵션들을 설정해보았다. 필수로 적용해야하는 옵션은 아니지만 설정해두면 좋은 옵션들이다.
- 다음 포스트에서는 XPATH를 이용하여 데이터를 수집해보도록 하겠다.
'Back-end > Python' 카테고리의 다른 글
| [크롤링] Selenium으로 특가 상품 수집 (4) - 모듈화 (0) | 2020.02.02 |
|---|---|
| [크롤링] Selenium으로 특가 상품 수집 (3) - 데이터 분석 및 수집 (2) | 2020.01.31 |
| [크롤링] Selenium으로 특가 상품 수집 (1) - 프로젝트 준비 (0) | 2020.01.31 |
| [Telegram] 무작정 시작하기 (3) - Button Message (0) | 2020.01.30 |
| [Telegram] 무작정 시작하기 (2) - CommandHandler (0) | 2020.01.30 |